Index Iterators¶
- Learning Objective
- You will know the different kinds of index indices and how to use them for searching.
- Difficulty
- Average
- Duration
- 1.5 h
- Prerequisites
- Sequences
Virtual String Tree Iterator¶
SeqAn provides a common interface, called the Virtual String Tree Iterator (VSTree Iterator), which lets you traverse the IndexSa, IndexEsa, IndexWotd and IndexDfi as a suffix tree (Indices definition), the IndexQGram as a suffix trie, and the FMIndex as a prefix trie. In the first part of this tutorial we will concentrate on the TopDown Iterator which is one of the two index iterator specializations (besides the BottomUp Iterator). The second part will then deal with the DFS.
Top-Down Iteration¶
For index based pattern search or algorithms traversing only the upper parts of the suffix tree the TopDown Iterator or TopDown History Iterator is the best solution. Both provide the functions goDown and goRight to go down to the first child node or go to the next sibling. The TopDown History Iterator additionally provides goUp to go back to the parent node. The child nodes in IndexEsa indices are lexicographically sorted from first to last. For IndexWotd and IndexDfi indices this holds for all children except the first.
In the next example we want to use the TopDown Iterator to efficiently search a text for exact matches of a pattern. We therefore want to use goDown which has an overload to go down an edge beginning with a specific character.
Important
The following examples show how to iterate IndexSa, IndexEsa, IndexWotd or IndexDfi, i.e. Index specializations representing suffix trees. The result of the iteration will look different on Index specializations representing tries, e.g. FMIndex or IndexQGram. Indeed, the topology of an Index changes depending on the chosen tree or trie specialization. Note that any suffix tree edge can be labeled by more than one character, whereas any trie edge is always labeled by exactly one character.
First we create an index of the text "How much wood would a woodchuck chuck?"
int main()
{
typedef Index<CharString> TIndex;
TIndex index("How much wood would a woodchuck chuck?");
Iterator<TIndex, TopDown<> >::Type it(index);
CharString pattern = "wood";
while (repLength(it) < length(pattern))
{
// go down edge starting with the next pattern character
if (!goDown(it, pattern[repLength(it)]))
return 0;
unsigned endPos = std::min((unsigned)repLength(it), (unsigned)length(pattern));
// compare remaining edge characters with pattern
std::cout << representative(it) << std::endl;
if (infix(representative(it), parentRepLength(it) + 1, endPos) !=
infix(pattern, parentRepLength(it) + 1, endPos))
return 0;
}
// if we get here the pattern was found
// output match positions
for (unsigned i = 0; i < length(getOccurrences(it)); ++i)
std::cout << getOccurrences(it)[i] << std::endl;
return 0;
}
Afterwards we create the TopDown Iterator using the metafunction Iterator, which expects two arguments, the type of the container to be iterated and a specialization tag (see the VSTree Iterator hierarchy and the Iteration Tutorial for more details).
Iterator<TIndex, TopDown<> >::Type it(index);
The main search can then be implemented using the functions repLength and representative.
Since goDown might cover more than one character (when traversing trees) it is necessary to compare parts of the pattern against the representative of the iterator.
The search can now be implemented as follows.
The algorithm descends the suffix tree along edges beginning with the corresponding pattern character.
In each step the unseen edge characters have to be verified.
CharString pattern = "wood";
while (repLength(it) < length(pattern))
{
// go down edge starting with the next pattern character
if (!goDown(it, pattern[repLength(it)]))
return 0;
unsigned endPos = std::min((unsigned)repLength(it), (unsigned)length(pattern));
// compare remaining edge characters with pattern
std::cout << representative(it) << std::endl;
if (infix(representative(it), parentRepLength(it) + 1, endPos) !=
infix(pattern, parentRepLength(it) + 1, endPos))
return 0;
}
If all pattern characters could successfully be compared we end in the topmost node who’s leaves point to text positions starting with the pattern. Thus, the suffixes represented by this node are the occurrences of our pattern and can be retrieved with getOccurrences.
// if we get here the pattern was found
// output match positions
for (unsigned i = 0; i < length(getOccurrences(it)); ++i)
std::cout << getOccurrences(it)[i] << std::endl;
return 0;
}
Program output:
w
wo
wood
9
22
Alternatively, we could have used goDown to go down the path of the entire pattern instead of a single characters:
if (goDown(it, "wood"))
for (unsigned i = 0; i < length(getOccurrences(it)); ++i)
std::cout << getOccurrences(it)[i] << std::endl;
return 0;
}
9
22
Tip
When implementing recursive algorithms such as an approximate search using backtracking, we recommend the use of the TopDownIterator without history. By passing the iterator by value, the history is stored implicitly on the call stack.
Assignment 1¶
- Type
- Review
- Objective
- Copy the code into a demo program and replace the text with a string set containing the strings
"How much","wood would"and" a woodchuck chuck?". - Solution
#include <iostream> #include <seqan/index.h> using namespace seqan; int main() { StringSet<String<char> > text; appendValue(text, "How much"); appendValue(text, " wood would"); appendValue(text, " a woodchuck chuck?"); typedef Index<StringSet<String<char> > > TIndex; TIndex index(text); Iterator<TIndex, TopDown<> >::Type it(index); CharString pattern = "wood"; while (repLength(it) < length(pattern)) { // go down edge starting with the next pattern character if (!goDown(it, pattern[repLength(it)])) return 0; unsigned endPos = _min(repLength(it), length(pattern)); // compare remaining edge characters with pattern std::cout << representative(it) << std::endl; if (infix(representative(it), parentRepLength(it) + 1, endPos) != infix(pattern, parentRepLength(it) + 1, endPos)) return 0; } // if we get here the pattern was found // output match positions for (unsigned i = 0; i < length(getOccurrences(it)); ++i) std::cout << getOccurrences(it)[i] << std::endl; return 0; }
The difference is the format of the positions of the found occurrences. Here, we need a Pair to indicate the string within the StringSet and a position within the string.
Assignment 2¶
- Type
- Review
- Objective
Write a program that traverses the nodes of the suffix tree of
"tobeornottobe"in the order shown here: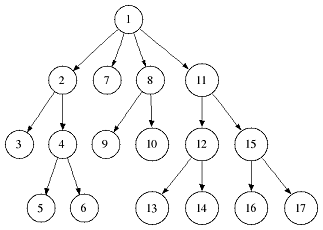
At each node print the text of the edges from the root to the node. You may only use the functions goDown, goRight, goUp and isRoot to navigate and representative which returns the string that represents the node the iterator points to.
- Hint
Use a TopDown History Iterator.
The code skeleton could look like this:
#include <iostream> #include <seqan/index.h> using namespace seqan; int main() { typedef Index<CharString> TIndex; TIndex index("tobeornottobe"); Iterator< TIndex, TopDown<ParentLinks<> > >::Type it(index); /* do { //... } while (isRoot(it)); */ return 0; }
- Solution
One iteration step of a preorder DFS can be described as follows:
if possible, go down one node
if not:
if possible, go to the next sibling
if not:
- go up until it is possible to go to a next sibling
- stop the whole iteration after reaching the root node
Thus, the DFS walk can be implemented in the following way:
#include <iostream> #include <seqan/index.h> using namespace seqan; int main() { typedef Index<CharString> TIndex; TIndex index("tobeornottobe"); Iterator<TIndex, TopDown<ParentLinks<> > >::Type it(index); do { std::cout << representative(it) << std::endl; if (!goDown(it) && !goRight(it)) while (goUp(it) && !goRight(it)) ; } while (!isRoot(it)); return 0; }
Assignment 3¶
- Type
- Review
- Objective
- Modify the program to efficiently skip nodes with representatives longer than 3. Move the whole program into a template function whose argument specifies the index type and call this function twice, once for the IndexEsa and once for the IndexWotd index.
- Solution
We modify the DFS traversal to skip the descent if we walk into a node whose representative is longer than 3. We then proceed to the right and up as long as the representative is longer than 3.
template <typename TIndexSpec> void constrainedDFS() { typedef Index<CharString, TIndexSpec> TIndex; TIndex index("tobeornottobe"); typename Iterator<TIndex, TopDown<ParentLinks<> > >::Type it(index); do { std::cout << representative(it) << std::endl; if (!goDown(it) || repLength(it) > 3) do { if (!goRight(it)) while (goUp(it) && !goRight(it)) ; } while (repLength(it) > 3); } while (!isRoot(it)); std::cout << std::endl; } int main() { constrainedDFS<IndexEsa<> >(); constrainedDFS<IndexWotd<> >(); return 0; }
be e o obe t be e o obe t
Depth-First Search¶
The tree traversal in assignment 2 is equal to a the tree traversal in a full depth-first search (dfs) over all suffix tree nodes beginning either in the root (preorder dfs) or in a leaf node (postorder dfs). A preorder traversal (Preorder DFS) halts in a node when visiting it for the first time whereas a postorder traversal (Postorder DFS) halts when visiting a node for the last time. The following two figures give an example in which order the tree nodes are visited.
Preorder DFS
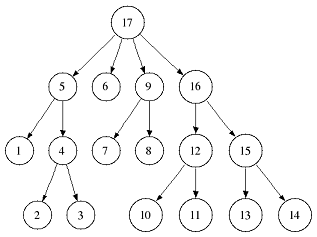
Postorder DFS
Since these traversals are frequently needed SeqAn provides special iterators which we will describe next.
We want to construct the suffix tree of the string “abracadabra” and output the substrings represented by tree nodes in preorder dfs. In order to do so, we create the string “abracadabra” and an index specialized with the type of this string.
#include <iostream>
#include <seqan/index.h>
using namespace seqan;
The Iterator metafunction expects two arguments, the type of the container to be iterated and a specialization tag, as described earlier.
In this example we chose a TopDown History Iterator whose signature in the second template argument is TopDown< ParentLinks<Preorder> >.
int main()
{
String<char> myString = "abracadabra";
typedef Index<String<char> > TMyIndex;
TMyIndex myIndex(myString);
Iterator<TMyIndex, TopDown<ParentLinks<Preorder> > >::Type myIterator(myIndex);
while (!atEnd(myIterator))
{
std::cout << representative(myIterator) << std::endl;
++myIterator;
}
return 0;
}
As all DFS suffix tree iterators implement the VSTree Iterator, they can be used via goNext, atEnd, etc.
Iterator<TMyIndex, TopDown<ParentLinks<Preorder> > >::Type myIterator(myIndex);
while (!atEnd(myIterator))
{
std::cout << representative(myIterator) << std::endl;
++myIterator;
}
return 0;
}
Program output:
a
abra
abracadabra
acadabra
adabra
bra
bracadabra
cadabra
dabra
ra
racadabra
Tip
There are currently 2 iterators in SeqAn supporting a DFS search:
| Iterator | Preorder | Postorder |
|---|---|---|
| BottomUpIterator | no | yes |
| TopDownHistoryIterator | yes | yes |
If solely a postorder traversal is needed the BottomUp Iterator should be preferred as it is more memory efficient. Please note that the BottomUp Iterator is only applicable to IndexEsa indices.
Tip
A relaxed suffix tree (see Indices) is a suffix tree after removing the $ characters and empty edges. For some bottom-up algorithms it would be better not to remove empty edges and to have a one-to-one relationship between leaves and suffices. In that cases you can use the tags PreorderEmptyEdges or PostorderEmptyEdges instead of Preorder or Postorder or EmptyEdges for the TopDown Iterator.
Note that the goNext is very handy as it simplifies the tree traversal in assignment 2 greatly.
Assignment 4¶
- Type
- Review
- Objective
- Write a program that constructs an index of the StringSet “tobeornottobe”, “thebeeonthecomb”, “beingjohnmalkovich” and outputs the strings corresponding to suffix tree nodes in postorder DFS.
- Solution
First we have to create a StringSet of CharString (shortcut for
String<char>) and append the 3 strings to it. This could also be done by using resize and then assigning the members withoperator[]. The first template argument of the index class has to be adapted and is now a StringSet.#include <iostream> #include <seqan/index.h> using namespace seqan; int main() { StringSet<CharString> myStringSet; appendValue(myStringSet, "tobeornottobe"); appendValue(myStringSet, "thebeeonthecomb"); appendValue(myStringSet, "beingjohnmalkovich"); typedef Index<StringSet<CharString> > TMyIndex; TMyIndex myIndex(myStringSet);
To switch to postorder DFS we have to change the specialization tag of
ParentLinksfromPreordertoPostorder. Please note that the TopDownHistoryIterator always starts in the root node, which is the last postorder DFS node. Therefore, the iterator has to be set explicitly to the first DFS node via goBegin.Iterator<TMyIndex, TopDown<ParentLinks<Postorder> > >::Type myIterator(myIndex); // Top-down iterators start in the root node which is not the first node of a // postorder DFS. Thus we have to manually go to the DFS start with goBegin goBegin(myIterator); while (!atEnd(myIterator)) { std::cout << representative(myIterator) << std::endl; ++myIterator; }
Alternatively with a TopDownHistoryIterator you also could have used a BottomUpIterator with the same result. The BottomUp Iterator automatically starts in the first DFS node as it supports no random access.
Iterator<TMyIndex, BottomUp<> >::Type myIterator2(myIndex); while (!atEnd(myIterator2)) { std::cout << representative(myIterator2) << std::endl; ++myIterator2; } return 0; }
Program output:
alkovich beeonthecomb beingjohnmalkovich beornottobe be b ch comb c ebeeonthecomb ecomb eeonthecomb eingjohnmalkovich eonthecomb eornottobe eo e gjohnmalkovich hebeeonthecomb hecomb he hnmalkovich h ich ingjohnmalkovich i johnmalkovich kovich lkovich malkovich mb m ngjohnmalkovich nmalkovich nottobe nthecomb n obeornottobe obe ohnmalkovich omb onthecomb ornottobe ottobe ovich o rnottobe thebeeonthecomb thecomb the tobeornottobe tobe ttobe t vich alkovich beeonthecomb beingjohnmalkovich beornottobe be b ch comb c ebeeonthecomb ecomb eeonthecomb eingjohnmalkovich eonthecomb eornottobe eo e gjohnmalkovich hebeeonthecomb hecomb he hnmalkovich h ich ingjohnmalkovich i johnmalkovich kovich lkovich malkovich mb m ngjohnmalkovich nmalkovich nottobe nthecomb n obeornottobe obe ohnmalkovich omb onthecomb ornottobe ottobe ovich o rnottobe thebeeonthecomb thecomb the tobeornottobe tobe ttobe t vich
As the last assignment lets try out one of the specialized iterators, which you can find at the bottom of this page. Look there for the specialization which iterates over all maximal unique matches (MUMS).
Assignment 5¶
- Type
- Review
- Objective
- Write a program that outputs all maximal unique matches (MUMs) between
"CDFGHC"and"CDEFGAHC". - Solution
Again, we start to create a StringSet of CharString and append the 2 strings.
#include <iostream> #include <seqan/index.h> using namespace seqan; int main() { StringSet<CharString> myStringSet; appendValue(myStringSet, "CDFGHC"); appendValue(myStringSet, "CDEFGAHC"); typedef Index<StringSet<CharString> > TMyIndex; TMyIndex myIndex(myStringSet);
After that we simply use the predefined iterator for searching MUMs, the MumsIterator. Its constructor expects the index and optionally a minimum MUM length as a second parameter. The set of all MUMs can be represented by a subset of suffix tree nodes. The iterator will halt in every node that is a MUM of the minimum length. The corresponding match is the node’s representative.
Iterator<TMyIndex, Mums>::Type myIterator(myIndex); while (!atEnd(myIterator)) { std::cout << representative(myIterator) << std::endl; ++myIterator; } return 0; }
Program output:
CD FG HC
Accessing Suffix Tree Nodes¶
In the previous subsection we have seen how to walk through a suffix tree. We now want to know what can be done with a suffix tree iterator. As all iterators are specializations of the general VSTree Iterator class, they inherit all of its functions. There are various functions to access the node the iterator points at (some we have already seen), so we concentrate on the most important ones.
- representative
- returns the substring that represents the current node, i.e. the concatenation of substrings on the path from the root to the current node
- getOccurrence
- returns a position where the representative occurs in the text
- getOccurrences
- returns a string of all positions where the representative occurs in the text
- isRightTerminal
- tests if the representative is a suffix in the text (corresponds to the shaded nodes in the Indices figures)
- isLeaf
- tests if the current node is a tree leaf
- parentEdgeLabel
- returns the substring that represents the edge from the current node to its parent (only TopDownHistory Iterator)
Important
There is a difference between the functions isLeaf and isRightTerminal. In a relaxed suffix tree (see Indices) a leaf is always a suffix, but not vice versa, as there can be internal nodes a suffix ends in. For them isLeaf returns false and isRightTerminal returns true.
Property Maps¶
Some algorithms require to store auxiliary information (e.g. weights, scores) to the nodes of a suffix tree.
To attain this goal SeqAn provides so-called property maps, simple Strings of a property type.
Before storing a property value, these strings must first be resized with resizeVertexMap.
The property value can then be assigned or retrieved via assignProperty, getProperty, or property.
It is recommended to call resizeVertexMap prior to every call of assignProperty to ensure that the property map has sufficient size.
The following example iterates over all nodes in preorder dfs and recursively assigns the node depth to each node.
First we create a String of int to store the node depth for each suffix tree node.
int main()
{
String<char> myString = "abracadabra";
typedef Index<String<char>, IndexWotd<> > TMyIndex;
TMyIndex myIndex(myString);
String<int> propMap;
The main loop iterates over all nodes in preorder DFS, i.e. parents are visited prior children. The node depth for the root node is 0 and for all other nodes it is the parent node depth increased by 1. The functions assignProperty, getProperty and property must be called with a VertexDescriptor. The vertex descriptor of the iterator node is returned by value and the descriptor of the parent node is returned by nodeUp.
Iterator<TMyIndex, TopDown<ParentLinks<Preorder> > >::Type myIterator(myIndex);
int depth;
while (!atEnd(myIterator))
{
if (isRoot(myIterator))
depth = 0;
else
depth = getProperty(propMap, nodeUp(myIterator)) + 1;
resizeVertexMap(propMap, myIndex);
assignProperty(propMap, value(myIterator), depth);
++myIterator;
}
At the end we again iterate over all nodes and output the calculated node depth.
goBegin(myIterator);
while (!atEnd(myIterator))
{
std::cout << getProperty(propMap, value(myIterator)) << '\t' << representative(myIterator) << std::endl;
++myIterator;
}
return 0;
}
Program output:
0
1 a
2 abra
3 abracadabra
2 acadabra
2 adabra
1 bra
2 bracadabra
1 cadabra
1 dabra
1 ra
2 racadabra
Tip
In SeqAn there is already a function nodeDepth defined to return the node depth.
Additional iterators¶
By now, we know the following iterators (\(n\) = text size, \(\sigma\) = alphabet size, \(d\) = tree depth):
| Iterator specialization | Description | Space | Index tables |
|---|---|---|---|
| BottomUpIterator | postorder dfs | \(\mathcal{O}(d)\) | SA, LCP |
| TopDownIterator | can go down and go right | \(\mathcal{O}(1)\) | SA, Lcp, Childtab |
| TopDownHistoryIterator | can also go up, preorder/postorder dfs | \(\mathcal{O}(d)\) | SA, Lcp, Childtab |
Besides the iterators described above, there are some application-specific iterators in SeqAn:
| Iterator specialization | Description | Space | Index tables |
|---|---|---|---|
| MaxRepeatsIterator | maximal repeats | \(\mathcal{O}(n)\) | SA, Lcp, Bwt |
| SuperMaxRepeatsIterator | supermaximal repeats | \(\mathcal{O}(d+\sigma)\) | SA, Lcp, Childtab, Bwt |
| SuperMaxRepeatsFastIterator | supermaximal repeats (optimized for ESA) | \(\mathcal{O}(\sigma)\) | SA, Lcp, Bwt |
| MumsIterator | maximal unique matches | \(\mathcal{O}(d)\) | SA, Lcp, Bwt |
| MultiMemsIterator | multiple maximal exact matches (w.i.p.) | \(\mathcal{O}(n)\) | SA, Lcp, Bwt |
Given a string s a repeat is a substring r that occurs at 2 different positions i and j in s. The repeat can also be identified by the triple (i,j,|r|). A maximal repeat is a repeat that cannot be extended to the left or to the right, i.e. s[i-1]≠s[j-1] and s[i+|r|]≠s[j+|r|]. A supermaximal repeat r is a maximal repeat that is not part of another repeat. Given a set of strings \(s_1, \dots, s_m\) a MultiMEM (multiple maximal exact match) is a substring r that occurs in each sequence \(s_i\) at least once and cannot be extended to the left or to the right. A MUM (maximal unique match) is a MultiMEM that occurs exactly once in each sequence. The following examples demonstrate the usage of these iterators: